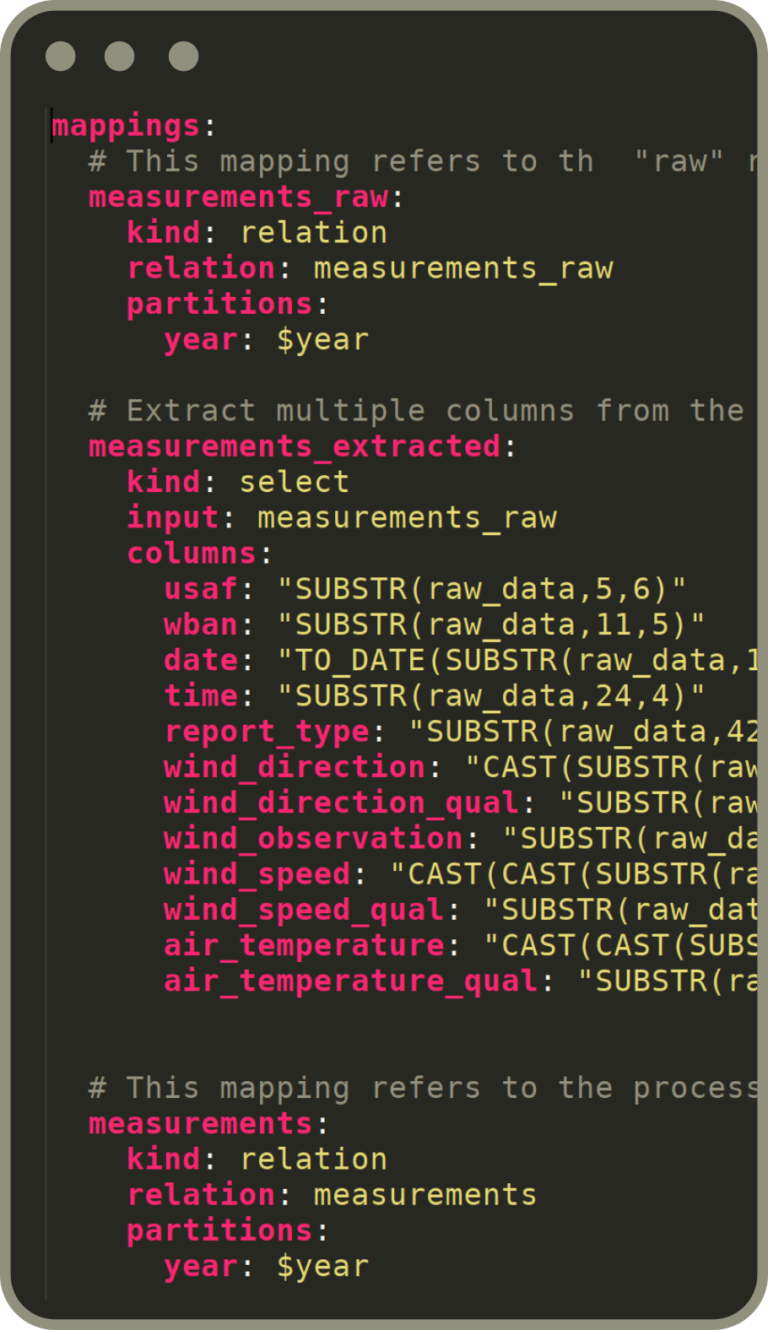
Flowman follows the "Everything-is-Code" approach. Therefore the development of all data flows takes place in a text editor of your choice. Since all Flowman entities like relations, mappings, targets and jobs are specified as simple declarative YAML files, any editor which supports YAML will work fine.
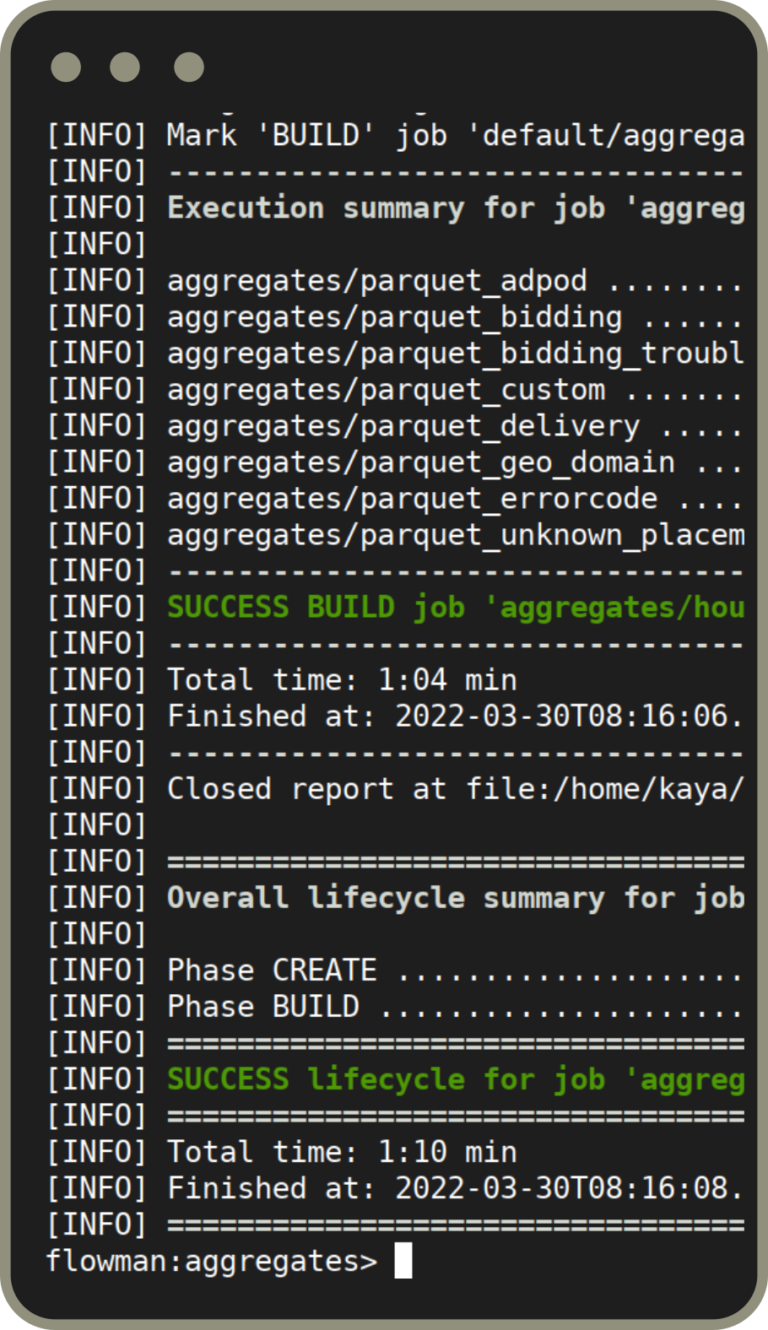
The execution of the Flowman project is performed with a powerful command line tools. These can be directly installed on your Linux machine and other OSes are well supported with pre-built Docker images.
In addition to the main tool for batch execution, Flowman also provides an interactive shell for development purpose which allows inspection of all entities and intermediate results.

All that Flowman needs are the YAML files of your project. This supports a simple deployment process to different staging environments (dev, test, prod) by transfering the project files to the corresponding systems.
By using environment and/or profiles, you can easily provide the details of each environment like dataabse server names etc.
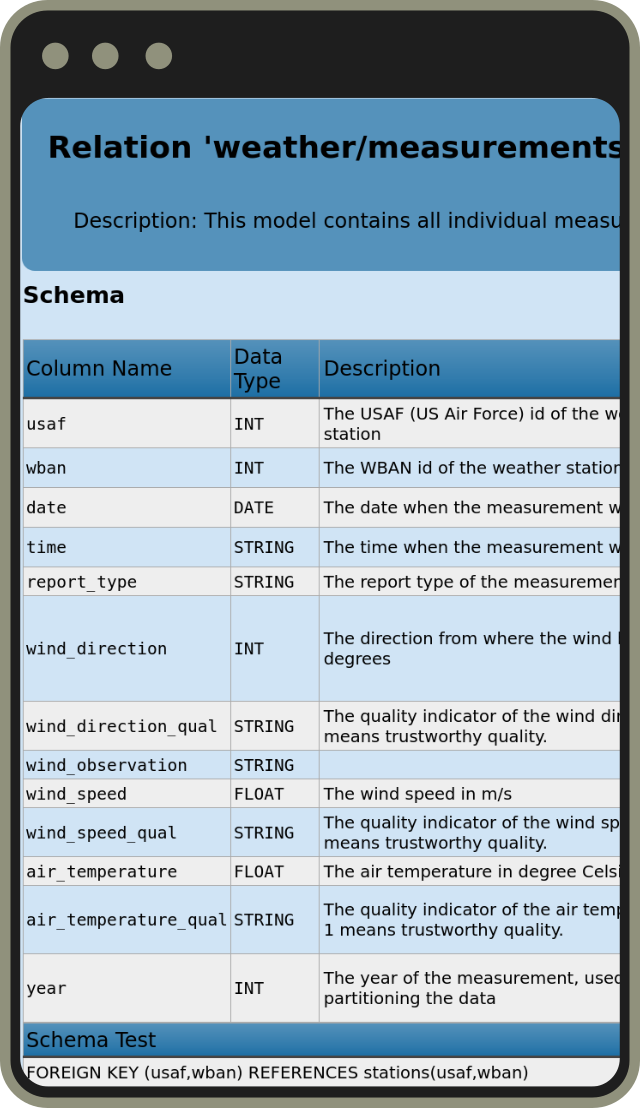
Test and document your project and your data by annotating mappings or relations with descriptions and with quality checks. Both can be done either on the entity level (mapping or relation) or even on the column level.
Flowman then easily generates a full blown documentation of your project, that will not only include your description, but also the results of all specified test cases. This minimizes friction between your assumption on the data and the reality.
Flowman follows the "Everything-is-Code" approach.
Therefore the development of all data flows takes place in a text editor of your choice. Since all Flowman entities like relations, mappings, targets and jobs are specified as simple declarative YAML files, any editor which supports YAML will work fine.
Read the reference documentation for writing Flowman code...
The execution of the Flowman project is performed with a powerful command line tools. These can be directly installed on your Linux machine and other OSes are well supported with pre-built Docker images.
In addition to the main tool for batch execution, Flowman also provides an interactive shell for development purpose which allows inspection of all entities and intermediate results.
All that Flowman needs are the YAML files of your project. This supports a simple deployment process to different staging environments (dev, test, prod) by transfering the project files to the corresponding systems.
By using environment and/or profiles, you can easily provide the details of each environment like database server names etc.
Test and document your project and your data by annotating mappings or relations with descriptions and with quality checks. Both can be done either on the entity level (mapping or relation) or even on the column level.
Flowman then easily generates a full blown documentation of your project, that will not only include your description, but also the results of all specified test cases. This minimizes friction between your assumption on the data and the reality.