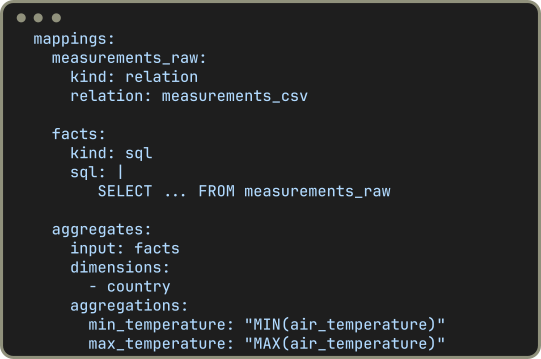
Split up complex chains of transformations into multiple small and testable steps. Manageable pieces of code are much simpler to design and understand than complicated nested SQL queries.
Split up complex chains of transformations into multiple small and testable steps. Manageable pieces of code are much simpler to design and understand than complicated nested SQL queries.
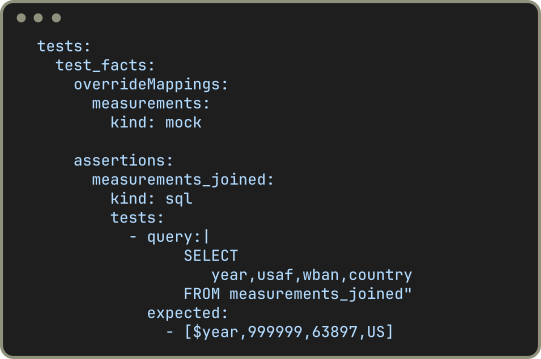
Test your business logic in an isolated environment without needing to access any external service. Mock external data sources by using the integrated test framework to verify the correctness of your logic with carefully crafted test cases.
Test your business logic in an isolated environment without needing to access any external service. Mock external data sources by using the integrated test framework to verify the correctness of your logic with carefully crafted test cases.
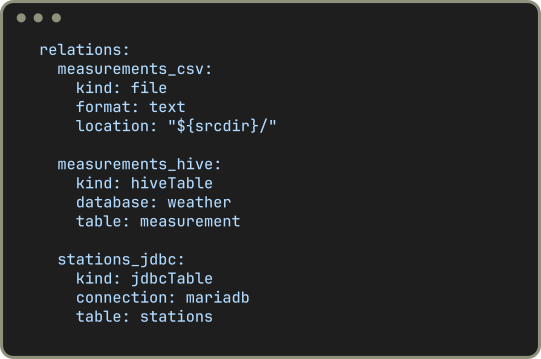
Connect many different data sources like relational databases and object stores in a single project. Easily join data from different data sources without the need to copy the data into staging tables before.
Connect many different data sources like relational databases and object stores in a single project. Easily join data from different data sources without the need to copy the data into staging tables before.

Start with small data and scale up your project with your ever-growing amount of data. Being built on top of Apache Spark, Flowman can easily scale processing from a single machine to possibly terabytes of data processed in a distributed cluster.
Start with small data and scale up your project with your ever-growing amount of data. Being built on top of Apache Spark, Flowman can easily scale processing from a single machine to possibly terabytes of data processed in a distributed cluster.

Easily integrate the code into your existing environment, like moving your pipeline descriptions from the development to the production stage. By relying on a simple standard text format (YAML), you are free to use the version control system of your choice and conduct code-reviews.
Easily integrate the code into your existing environment, like moving your pipeline descriptions from the development to the production stage. By relying on a simple standard text format (YAML), you are free to use the version control system of your choice and conduct code-reviews.