Flowman 1.1.0 released
We are happy to announce the release of Flowman 1.1.0. This release contains many small improvements and bugfixes. Flowman now finally supports Spark 3.4.1. Major

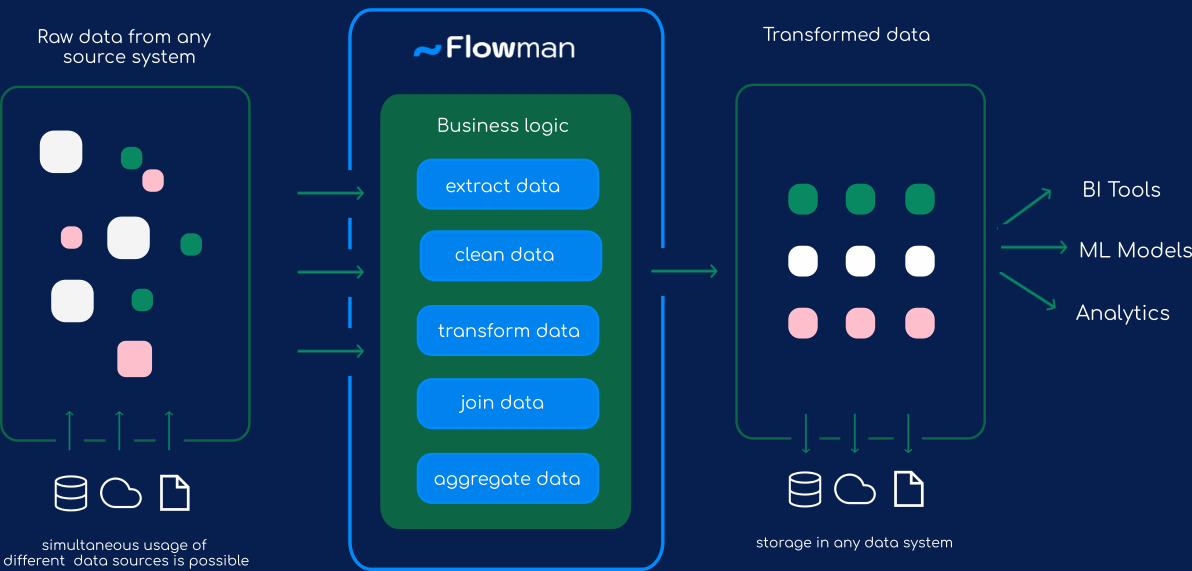
Lightweight specification of data models, transformations and build targets using declarative syntax instead of complex application code.
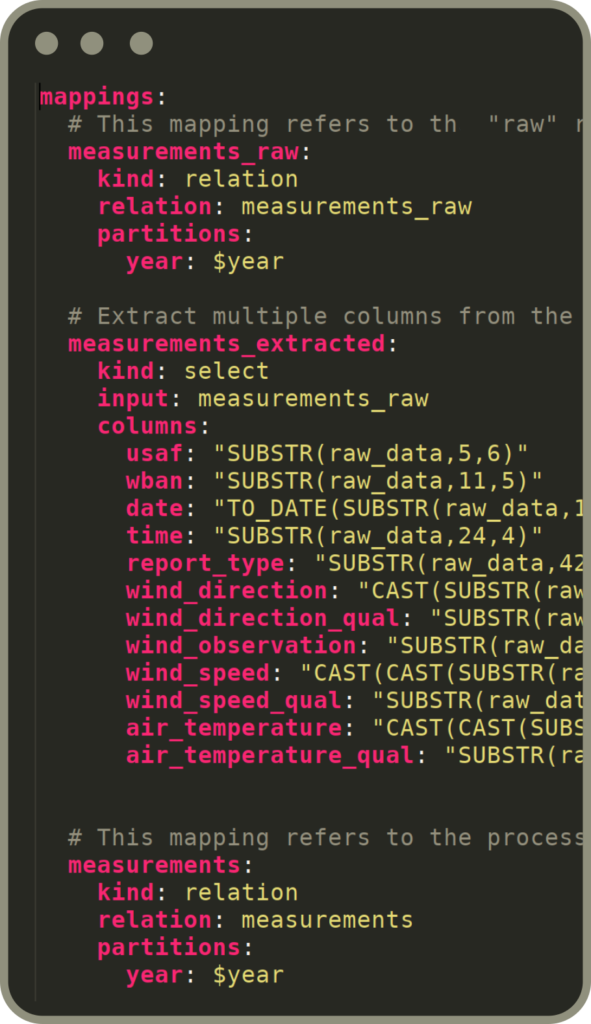
Modern development methodology following the "everything is code" approach supporting collaboration via arbitrary VCS. Support for self contained unittest, automatic documentation and data quality checks.
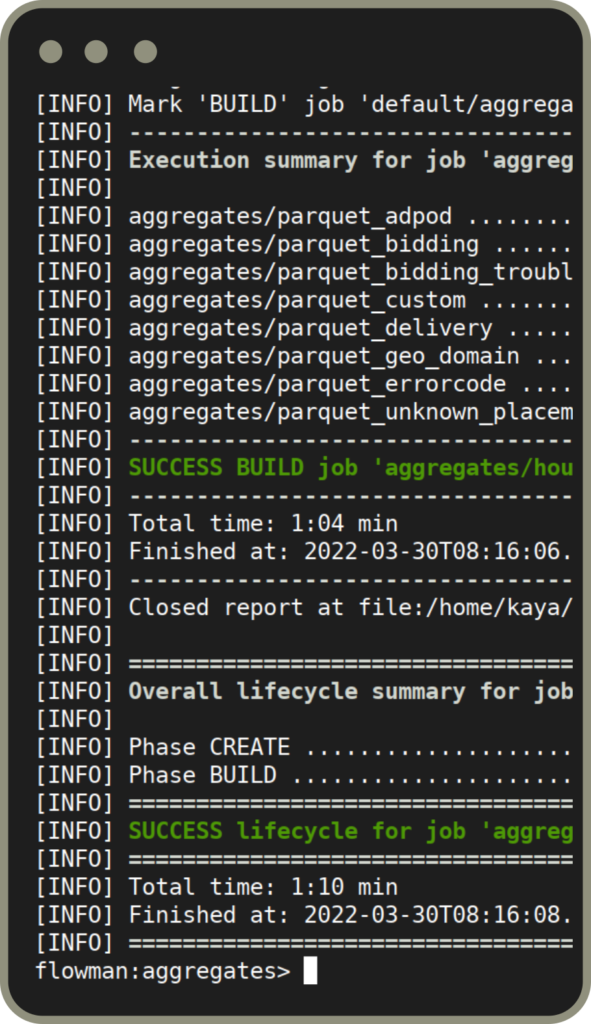
Full lifecycle management of your data models, including creating target tables, automatic migration, and possibly final removal. Automatic documentation of data flows including lineage and quality checks. Job history server. Business defined execution metrics.

Implement complex transformations step by step, create self-contained unit tests at any point in the chain of transformations. Flowman will execute the whole flow without sacrificing performance by applying end-to-end query optimizations.
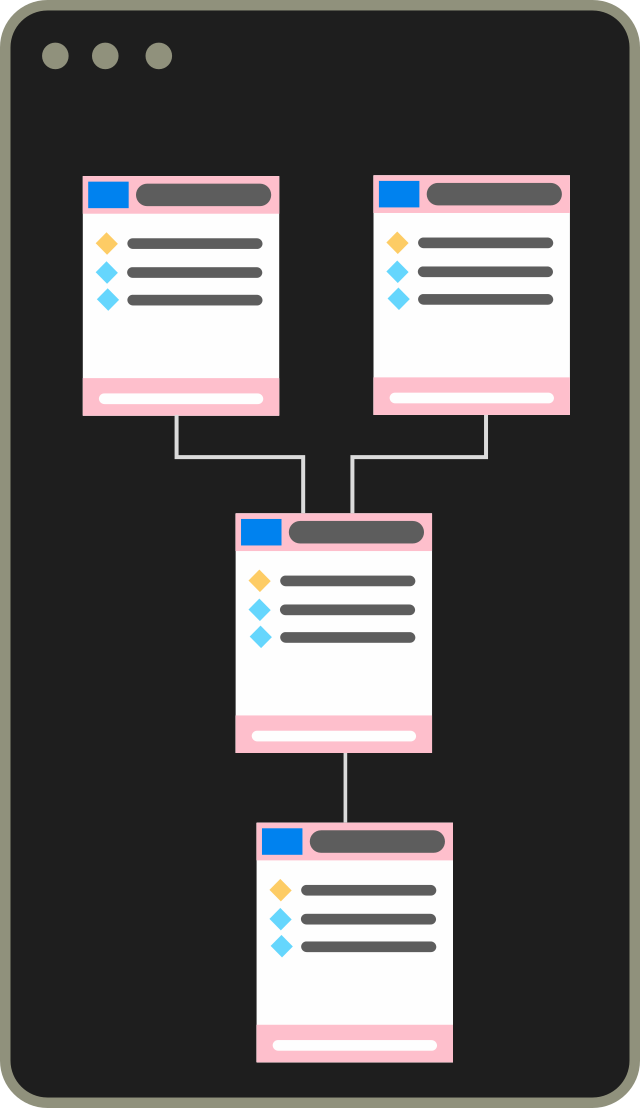
Design all details of your data models, grow and evolve them over time. Add descriptions and expectations to columns. Flowman will create the physical model including descriptions and automatically migrate existing tables to the desired state.
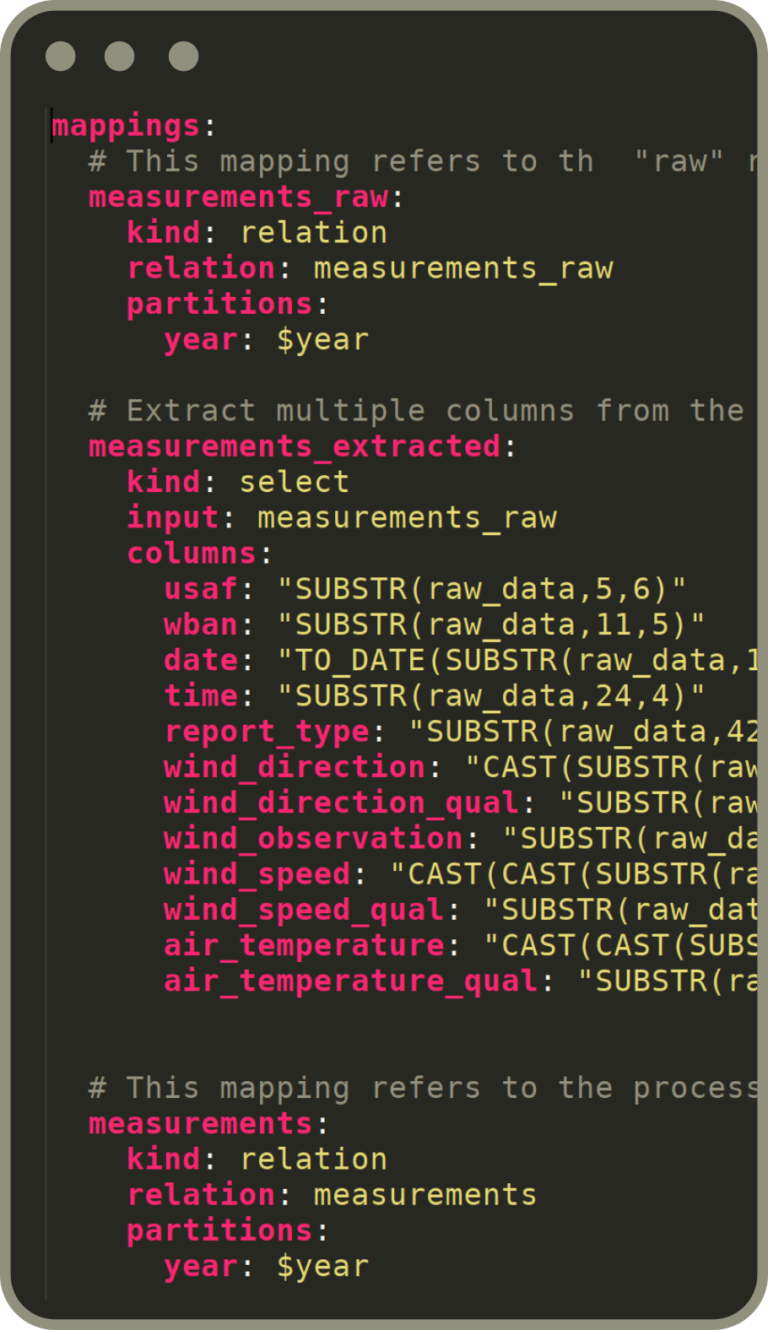
Implement complex transformations step by step, create self-contained unit tests at any point in the chain of transformations. Flowman will take care of executing the whole flow without sacrificing performance by applying end-to-end query optimizations.
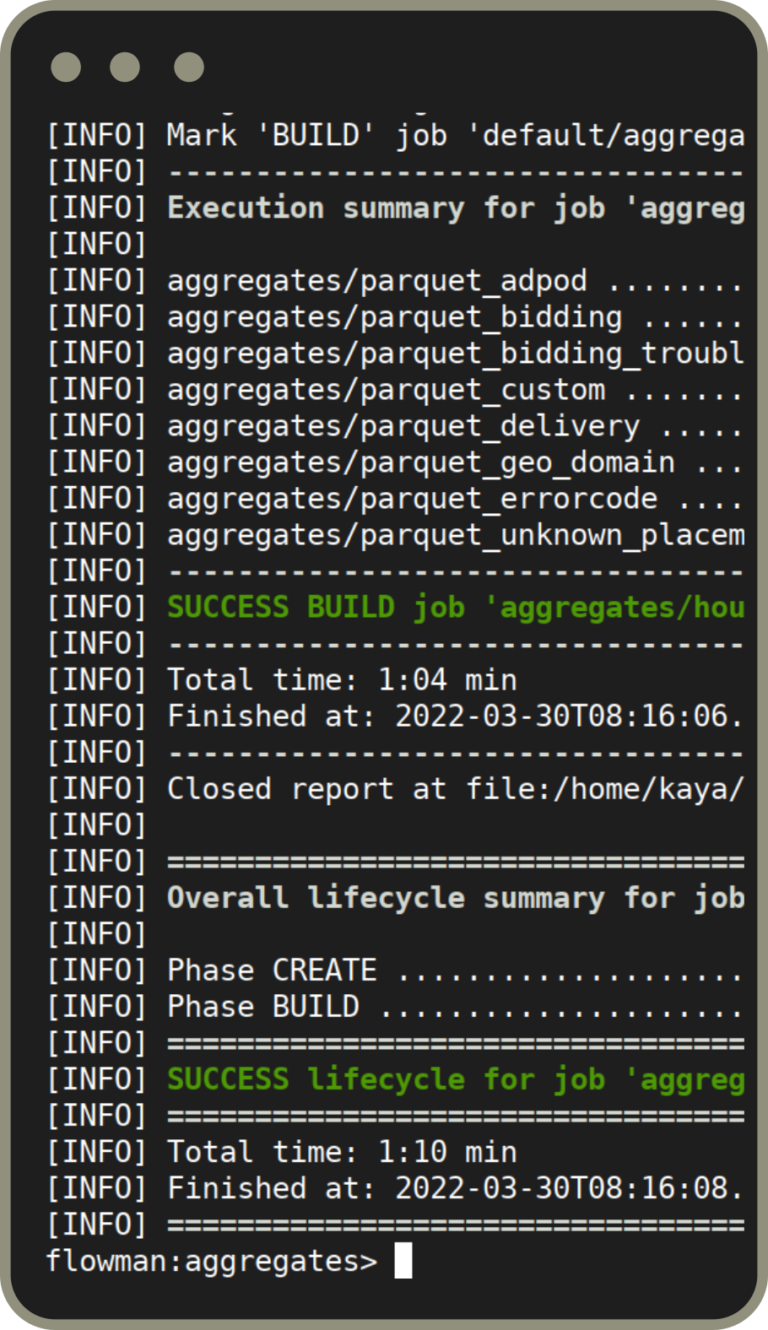
Implement self-contained unit tests for your business logic by mocking the real data sources. Add data quality checks before and after pipeline execution. Collect meaningful execution metrics including data quality.